|
More Fun with Chemical Catalog(ue)s
John Bradshaw
|

|
|
More Fun with Chemical Catalog(ue)s
John Bradshaw
|
|
History. The age of the paper catalogue.
"Research chemists involved in the synthesis of novel organic compounds need chemical intermediates and spend valuable time searching through suppliers catalogues for useful compounds"
S. Barrie Walker J. Chem. Inf. Comput. Sci. (1983), 23(1), 3-5.
The quotation above is from the paper (Development of CAOCI and its use in ICI plant protection division. Walker, S. Barrie. J. Chem. Inf. Comput. Sci. (1983), 23(1), 3-5) describing work started over 10 years earlier at ICI Plant Protection Division in the UK, to make available, to practising chemists, a database of Commercially Available Organic Chemicals. With colleagues in the U.K. Chapter of the Chemical Notation Association (CNA (U.K.)), they discussed the problem that there were multiple names for the same compound in the various (paper) catalogues from suppliers. What was required was a single, unique name with links, to the various local names, which existed in the catalogues. They decided that this name should be derived from the structure and came up with the idea of using the Wisswesser Line Notation (WLN) to provide that name. ICI had produced an index of 20 000 organic chemicals from 10 small catalogues as a prototype in early 1973, and along with colleagues from the pharmaceutical companies
they set about producing a more comprehensive index. ICI used their CROSSBOW programs ( Eakin, D.R. In "Chemical Information Systems" Ash, J.E., Hyde, E., Eds.; Ellis Horwood Ltd.: Chichester; (1975) Chapter 14) to establish and maintain the file. By 1976 the members of the consortium had hard copy molecular formula and WLN-ordered indices. These were available as microfiche , with about 50 000 records from 18 suppliers giving information on 20 000 compounds.
Those companies who had the CROSSBOW suite of programs were also able to do "substructure" (sic) searches.
With the sole exception of the Aldrich Chemical Company, who did provide a file to ICI, all the entry and updating was done from the hard-copy catalogues. Walker remarks in his paper that, "despite considerable correspondence" there was "an unwillingness on the part of the suppliers" to provide update information. A new catalogue meant therefore, laboriously checking whether the compounds were still in the file. A decision was taken not to delete compounds from the file, as, quite often, particularly if there was only one source of the material, further supplies could be had. They were simply marked "withdrawn".
In 1979, after much discussion the file was handed over to Fraser Williams (Scientific Systems) for continued maintenance and distribution to other companies. (See Rosenberg, Murray D.; DeBardeleben, Marian Z.; DeBardeleben, John F. Chemical supply catalog indexing: now and the future. An ideal place for use of the Wiswesser line notation. J. Chem. Inf. Comput. Sci. (1982), 22(2), 93-8 for a review of the use of CAOCI outside the consortium group). At that time there were about 120 000 references to 42 000 available chemicals from 48 suppliers. The acronym CAOCI was discarded in favour of the Fine Chemicals Directory FCD.
With the replacement of WLN by graphical input of structures, ownership of the database passed to MDL. The data are commercially available as Available Chemicals Directory (ACD) This covers "240 000 substances representing 690 000 chemical products from 500 suppliers". This is also available from DAYLIGHT.
The present. Catalogues go electronic.
With the advent of high throughput screening (HTS) in the pharmaceutical and allied industries, the demand for small quantities of large numbers of compounds has increased. To a certain extent, this demand has been fulfilled by combinatorial chemistry. However, the restricted chemistries available and the very nature of combinatorial synthesis, i.e. the production of large numbers of related compounds, meant that there was still a commercial need for large numbers of appropriate, diverse, organic chemicals.
During the early 1990's, therefore a large number of suppliers grew up to satisfy this need. Many of them providing compounds ready for test in formatted plates, totally abandoning any attempt to provide quantities of compound as chemical intermediates. These 'new-kids on the block' had to compete to sell their goods, and one of the most effective ways was to supply electronic copies of the connection tables, for the structures they were offering, free of charge.
As customers we needed to see whether these products met our needs. Our first approach was to design a triage system, which would allow us to make a decision on whether to accept or reject a collection on the following bases
The results could easily be displayed as a series of pie charts. More details of this were presented at EuroMUG'98.
Our ability to do this was predicated on the vendors supplying connection tables electronically. With the increasing numbers of vendors supplying larger and larger number of compounds it became vital that we had a single source, to view and to compare the structures. We had effectively replaced a shelf full of catalogues with a hard disk full of ISIS databases.
To give you some idea here is a picture of a few months offering of databases. This does not include the multiple linked emails 
We have no control on how the vendors choose to represent their structures or what data they associate with each entry. As we had successfully operated a Parent > Isomer > Version hierarchy in our registry system for several years, this formed the basis of our plan. The 'business rules' for structure representation have been outlined earlier in detail.
However, basically what we have done is to opt for a datawarehouse model where the process of cleaning the data applies the business rules to standardise the structural representation, but we retain the originator's valence bond representation and data associated with the structure at the version level. By making use of the THOR model, i.e. carefully assigning identifier and data items and rigorously applying the rules about the relationships between them, we have a system, which allows us to ask questions across suppliers' databases. This warehouse has data from ~2 000 000 samples representing ~1 000 000 parent structures from 38 suppliers. Internally this has become known as BACD Beyond the ACD.
Example pages corresponding to the microfiche version are
Z-L-isoleucyl-valine
and
3-(diethylamino)-propyl 3-methyl-2-(ortho-tolyl)-valerate hydrochloride
There is a commercial collection of some of these databases available from MDL (ACD-SC), with 938 000 compounds and 580 000 unique structures from 20 suppliers.
As the numbers of compounds are so large, we have not worried too much if we have lost the odd compound. This may be from quirky representations from a supplier, to occasions where our business rules fail. Such a failure is illustrated if you look up picric acid (Oc1c(cc(cc1N(=O)=O)N(=O)=O)N(=O)=O ). Sigma Aldrich sell a large number of picrates of small amines, which the parent algorithm we use discards the amine portion. However because we have not thrown away the original data the supplied salt can still be retrieved from the version data. In this particular case we chose not to fix anything as the idea of testing picrate salts did not appeal to our screeners. In our registry system we have a THOR(naturally!!) database of counter ions etc which are added to as appropriate.
A major requirement, if this sort of compound acquisition is to form a useful part of our strategy for maintaining and developing our compound collection, is that we have some feel for what proportion of compounds offered are unique to one supplier i.e. we have not been offered them before. This should then allow us to ascertain whether this is a sustainable strategy or whether, in a few years time, the number of novel compounds being offered will drop to an unacceptably low level.
If there really are 1020 appropriate compounds out there, then you really would expect any sample selected to be unique, even if the sample were as large as 106. The sampling by synthetic chemists is not totally random, so we find that the frequency of choosing something, which has already been offered by another supplier, like many other things in life, (Zipf, George K.; "Human Behaviour and the Principle of Least-Effort", Addison-Wesley, Cambridge MA, 1949) follows a Zipfian curve. The most common case (rank 1) is that the compound is available from one source, the next best from 2 sources etc. In their 1982 paper Rosenberg et al had commented that the supplier frequencies exhibited a "Zipfian or Bradford 80/20 rule distribution". I.e. most compounds were only available from one supplier, a few "common" compounds were available from all/many suppliers.
Below is an overlaid plot, with time, of the proportion of the parent compounds against the number of suppliers offering that parent in some form or other (isomer, salt etc).
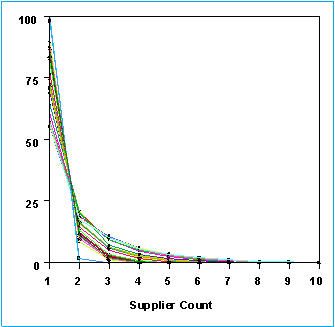
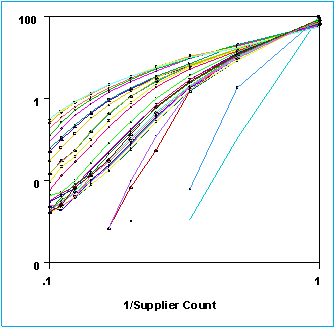
As can be seen, even after 38 suppliers have been added, in excess of 55% of parent structures are available only from one supplier. This is clearer if we do a proper Zipfian plot where the probability P(s) of a compound being available from s suppliers is
P(s) = c/s
Where c is a constant.
Current values of c are 61(± 6)% after 38 suppliers.
S37 By 1/Supplier Count
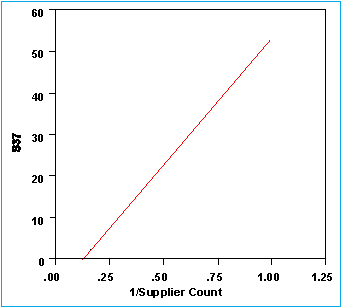
S37 = -7.9104 + 61.0001 1/Supplier Count
Whilst we are taking heart from the fact that 60% of any incoming data set from new supplier is likely to be new, it also implies, as company systems register more and more compounds, that there is a 40% chance a compound has been seen before. This has implications for registry system design.
The process of addition of a new catalogue can be demonstrated.

|

|

|
|

|
| Suppliers file | Convert to SMILES | SMILES rooted trees | Make parent and reroot | THOR datatrees delivered to tcp/ip |
We too have adopted the policy of not deleting records. This is facilitated by the power of the indirect database. By assigning suppliers catalogues as indirect data items we can update as new copies versions are delivered.
So a record like
$I<S38;Current Tocris Cookson>|
when a new catalogue comes along, becomes
$I<S38;Tocris Cookson 1998>|
and we add
$I<S45;Current Tocris Cookson>|
The original data remains associated with the original catalogue entry. For the user, the current catalogue continues to be displayed as Current Tocris Cookson. Eventually this will become "Tocris Cookson 1999". If the supplier has very few additions then the only increase in database size is the single line indicating the new catalogue name. The thorload merge procedure handles the rest. The constant supply. i.e. availibility over many years, may influence the users decision to choose it. We have not yet reached this point but we could make use of the _P flag in the datatypes file to restrict the optional suppliers which are searchable.
Retaining all the records allows a second use for BACD as a sample of appropriate synthesisable compounds for use in a program like savant.
The future. Catalogues as information sources.
So what of the future? Current experience would tell us that there is still a large number of untapped compounds out there. In the dataset described here there is a 60% chance that any compound is available from only one supplier. We are working with some of our statistician colleagues to see if we can estimate how long it will be at current sampling rates from chemical space before the proportion of new compounds becomes unacceptably low.
What we really need to be looking at are the ways in which we choose compounds from these large datasets. At MUG'98 we talked about work which allowed us to mix structural data and text or numeric descriptors to assess whether compounds were like a prototype. Chemical catalogues are rich sources of this non-structural information. Quite often there are physicochemical data or information about the bioactivity of a compound. In many cases there are references to the original literature. For example, if we take a sample page of the Tocris Cookson catalogue.
Normally the non-structural data are omitted from the SD files that are distributed, mainly because of the difficulty of adding free text into the MDL format. There would also be unacceptable overheads on searching using Hviews in ISIS. However, we were able to take the AdobePagemaker version of the catalogue, kindly supplied by Tocris, and produce a Daylight THOR database, this maintains the full information content of the printed version and there are no overheads in searching text, data and structure together.
A prototype is available for the meeting. An example page is here
When this is merged into our datawarehouse it allows scientist to make ad hoc queries through interfaces such as xvmerlin() or the web tool Wizard or our favo(u)rite, daybase . It also provides a rich source for datamining. For instance, the Tocris catalogue provides some information about DMSO and water solubility. A scientist may wish to risk the conclusion that compounds structurally similar to those reported to be soluble in DMSO and or water are more likely to exhibit such solubility properties than those which are less structurally similar --- irrespective of whether they are available from Tocris or not. This could affect the choice of compounds for purchase/test.
If more suppliers could be persuaded to make the text available, all the small bits of data about the structural identifier could be merged into a powerful resource. Many catalogues list links into spectral and safety information along with anecdotal comments which could all add to deciding which compounds to choose. The THOR framework allows information about relevant molecules to be brought together and used, even if the physical sample of the compound is not purchased.
The ability to filter out unlikely/impossible candidates has always been at the heart of chemical structure searching. In the future, hopefully, we can use an amalgam of structural and non-structural data to make the best-informed choice.
We would like to thank Ms Lacia Ashman for the copy of the 'text' portion of the Tocris Cookson catalogue as an Adobe Pagemaker file, and for permission to demonstrate the combined database at MUG'99
|
support@daylight.com |

John Bradshaw. |
{kind=link}
{kind=link}
{kind=link}