 .
.John Bradshaw
Daylight CIS Inc., Sheraton House, Castle Park, Cambridge, CB3 0AX, UK
Following a talk at MUG '99 meeting at which the concept of a Virtual Chemical Stores/Stockroom was introduced, Daylight agreed to explore the possibility of producing a commercial product that would allow the information, present in electronic compound catalogues, to be made available in consistent format to end-users. The data model drew strongly on the Thor datatree structure and the compound hierarchy used in the Modgraph Compound Registry system. The original concept was to build a large single Thor database, however the data model allows alternatives such as Virtual Databases, in which the constituent databases are not merged, or using the Oracle cartridge retaining the compound hierarchy by judicious use of tables. A further option is to merge, the results of the query across multiple consistent databases, with a client.
The major sources of data are still the compound vendors, in particular those providing compounds for screening. Data are generally provided in the form of MDL sd files. However as the concept is not limited to commercially available compounds, other sources, such as the World Drug Index, or the NCI database would benefit from this approach.
A decision has been made to provide a product which will allow customers to build their own database by providing tools which will either produce Thor datatrees for loading into a Thor-Merlin system or SQL*Plus scripts to produce an Oracle database. There is also an option to produce a flat source which allows users to incorporate into an existing system or their own proprietary system. The earlier model has been improved so that now there is a predefined set of datatypes (Thor) or columns and tables (Oracle) into which any new data source can be added. We can therefore provide the datatypes database (Thor) or the schema (Oracle). In addition there is no longer a need for an external Thor database when building the input. It is hoped this product will be released in version 4.8.
The aim of most chemical suppliers' information handling is to produce a printed catalogue. So the fundamental data unit in this model is the catalogue entry from a particular supplier, which will be identified by some arbitrary string such as 0800, "BAS 00123" etc. Associated with this identifier will be items such as a chemical structure, a chemical name, and possibly other data. The suppliers will also use this identifier for their inventory and supply systems.
It is these records which forms the basis of the MDLI sd file which
suppliers distribute to potential customers usually on CD.
.
For example, if we take a sample page of the Tocris catalogue, we find
0774 identifying a sample with a name 4-[3-(Benzotriazol-1-yl)propyl]-1-(2-methoxyphenyl)-piperazine maleate with a molecular weight of 467.52. We also learn that this compound is "A potent pre- and postsynaptic 5-HT 1A receptor antagonist." and a reference to this property, Mokrosz et al (1994) Structure-activity relationship studies of central nervous system agents. 13. 4-[3-(Benzotriazol-1-yl)propyl]-1-(2- methoxy)piperazine, a new putative 5-HT 1A receptor antagonist, and its analogues. J.Med.Chem. 37 ,2754. In addition there is a chemical structure corresponding to the systematic name.
Note that the compilers of the catalogue imply that the property of "A potent pre- and postsynaptic 5-HT 1A receptor antagonist." belongs to the sample they offer for sale. It is unlikely they have tested the particular sample they send out to you. The authors of the paper ascribe the property to what we will be referring to as the parent molecule, the maleic acid plays no part in this. It is implied that the property of activity at 5-HT 1A receptors is inherited by the version molecule and will be exhibited by any subsequent sample you buy of this version. On the other hand the molecular weight of 467.52 is data about the version molecule and will also be exhibited by any subsequent sample you buy of this version. As the data are so confused in the supply source, it is unlikely that any automatic system will unravel it. It needs to be dealt with, without prejudice.
The point to remember is that these identifiers are the link to the only items which have a real existence, everything else in this model is information and data i.e. they are the names which the customer uses to communicate with the supplier when
placing an order for samples of chemicals such as these.

In general, all constituents of a multi-component compound are not equally important for the process in hand. If we restrict ourselves to some sort of biological assay or property measure such as logD or pKa, then these are easily understood as reflecting the presence of a parent molecule. Data such as aD reflect the presence of isomeric parent molecule. Note that neither of these parent molecules have an independent existence as a physical entity, in the Daylight sense they are identifiers or names, about which, data exist.
Data such as melting point are clearly about a particular sample, as are the experimental results of both physicochemical and biological assays. A version molecule structure may also have been assigned to this sample perhaps a salt or solvate or even a impure isomer.
Calculated data such as cLogP are about the parent molecule, whereas a rubicon structure is a datum about the isomeric parent. An x-ray structure on the other hand is a datum about the sample, and is related to the version structure. Molecular formulae or weights can refer to version or parent and thus must be clearly defined. Note that the sample is identified by some arbitrary name, in the current case by the supplier. The version structure is a datum about the sample identifier, it does not differ in principle from any other data assigned to the (hopefully ) white crystalline powder.
As we are interested in a chemical information system we can use this hierarchy of structures to group the data together in a dendrite model. The sample identifiers can be grouped by the isomeric version structure. As there are many suppliers of a particular compound, there is a many to one relationship between sample identifier and isomeric version structure. As the valence bond model for representing a compound is not unambiguous, the isomeric version structures can be grouped by normalized isomeric version structures. If, as implied above, not all the components of a compound are equally important, we can group the normalized isomeric version structures by the isomeric parent structure. Above this there is a many to one relationship between these isomeric parent structures and a parent structure which contains no stereochemical or isomeric information
It is also important to note that whilst the structure assigned to the sample may be the same as either the parent or isomeric parent, that is purely coincidental. This strict hierarchy ensures that the data are associated with the correct identifier in the tree, or key. This can be illustrated using the depict algorithm.
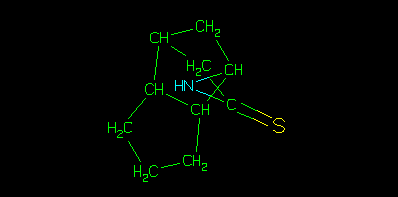
The above picture is generated from the parent smiles using smi2gif(), much like clogP would be using clogp(). Whereas
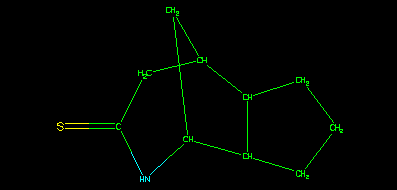
is generated from the version smiles and the associated 2D coordinates, still using smi2gif().
A benefit of this model is that data, which come from a flat file such as an sd file, can be restrained within a Thor subtree, or in a row in an ORACLE table, associating the supplier's data only with the supplier's identifier, not with a particular structure. In fact it is necessary to use two tables in ORACLE as, a priori we have no knowledge of the number of data items about a particular sample vide ultra.
A further benefit of this model is that we now have total control over the relationships between structure and data and can make sure only appropriate values are stored.
A set of routines have been written to calculate useful properties of molecules directly from the structures. These values can then be stored along with the structure from which they were derived. These functions are available via a program_object interface which allows them to be called from within DayCart®. The ones, which are not grayed out, are included in the VCS building routines, calculated from the parent smiles. All values are returned as part_tuples except for PART_COUNT which is an integer. If the SQL output is chosen numeric part_tuples are set to NULL
The following are included in the VCS building routines, calculated from the parent smiles. All values are returned as a part_tuple. The depiction is only returned if there are no 2D data in the input file.
The structure representation is normalized by a few simple rules. Note that this only affects the grouping of compounds, it does not affect the original representation which is maintained or affect any in-house display business rules.
Parent isomeric structures are created from the normalized version isomeric structure by the following steps.
If there are no components left, i.e. all components are in the salt table there is a roll-back of the last step to give a structure which is treated like a mixture. If there is more than one component this structure is treated like a mixture.
In the case of a mixture, in the current version, all possible single parents are generated plus the multicomponent parent. I.e. there is a one to many relationship between the child and the parent. In a registration system, the registrar may take on the Solomon role, and keeps the simple tree structure to the data model. In the absence of other information, all potential parents are treated equally. This means duplication of data in a Thor model and spawns yet another table in Oracle.
Questions have been raised why we need such a complex model. What is wrong with simply grouping on matching version valence model as in ACD? Aside from the value of classification and the fact that most chemical structure searches are at what we have described as the parent level, there are maintenance issues. Below are the fixes to the Tocris 2001 catalogue, in this model changes are constrained to the subtree in Thor or the row in Oracle as they are changes to the data about the catalogue number.

As was described in the introduction, this model fits well into the Thor paradigm. There are limitations as to the level of nesting but a typical tree showing the relationships in the data is shown here. Note that the data about the sample is stored in a sub-tree rooted in the normalized primary supplier identifier. There is a user-controlled list, per catalogue, of secondary identifiers. All data from the supplier is stored in a two field datatype
As a rather obtuse example the following SQL*Plus script will find the parent and version isomeric structures along with their catalogue number and name and the hydrogen bond donor profiles for fairly rigid compounds which are known toxins.
SELECT
sample.pism,
sample.vism,
sample.vcs_name,
sample_data.data_value,
parent.h_donor,
parent.h_accept
FROM
sample_data,
sample,
parent
WHERE
parent.rigidity > 0.9
AND
sample_data.data_name LIKE '%NAM%'
AND
sample_data.data_value LIKE '%toxin%'
AND
sample.par_id = parent.par_id
AND
sample.vcs_id = sample_data.vcs_id
;
Running this query against the tocris2001 database gives
| Parent | Version | Catalogue Number | Compound name | H-donors | H-Acceptors |
| 1128 | Picrotoxin (a 1:1 mixture of picrotoxinin and picrotin) | 1 | 12 | ||
| 1128 | Picrotoxin (a 1:1 mixture of picrotoxinin and picrotin) | 2 | 14 |
This illustrates the handling of mixtures. Note the predicate parent.rigidity > 0.9 only selects rows which have a non-NULL rigidity value. It is difficult to interpret a rigidity figure for a mixture, so it is set to NULL. As indicated above properties like part-count do have meeting and are filled for mixtures.
Demo versions under Oracle ( help here ) and Thor are available during the meeting. The Thor version is a sample from approximately 40 sources including the aids set from NCI. Under DayCart we have a single supplier Tocris 2001.
Daylight Chemical Information Systems, Inc.
info@daylight.com