EUROMUG 2000 19-20th September 2000
INTRODUCTION
Following a talk at last year's MUG meeting at which the concept of a Virtual Chemical Stores/Stockroom was explored, Daylight agreed to explore the possibility of producing a commercial product that would allow the information present in electronic compound catalogues to be made available in consistent format to end-users. By careful design of the data model the information could be delivered by WWW technology from the Daylight server but also be appropriate to be taken in-house and provide the basis for an expanded private system, queried by bespoke clients. The data model drew strongly on the THOR datatree structure and the compound hierarchy used in the Glaxo Wellcome Compound Registry system. The original concept was to build a large single THOR database, however the data model allows alternatives such as Virtual Databases, in which the constituent databases are not merged, or using the Oracle cartridge retaining the compound hierarchy by judicious use of tables. A further option is to merge the results of the query in a client. An example of this will be shown later in this talk.
SOURCES OF DATA
The major sources of data are still the compound vendors, in particular those providing compounds for screening. Data are generally provided in the form of MDL sd files. However as the concept is not limited to commercially available compounds, other sources, such as the World Drug Index, or the NCI database would benefit from this approach.
The NCI AIDS data file is available in this format for the meeting.
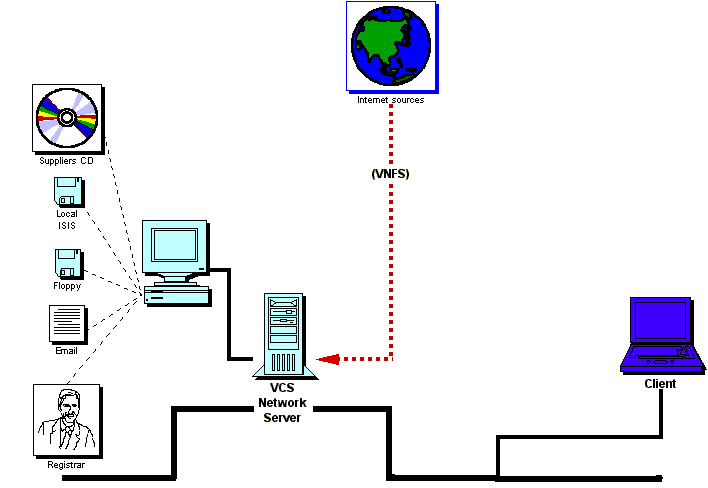
Most compound vendors supply in a variety of formats usually on a CD, but hopefully if the right links, both electronic and contractual can be put in place, use could be made of more dynamic transfer protocols such as VNFS. Again both the central Daylight public pantechnicon as well as the private in-house databases would benefit from this technology.
COMPOUND HIERARCHY
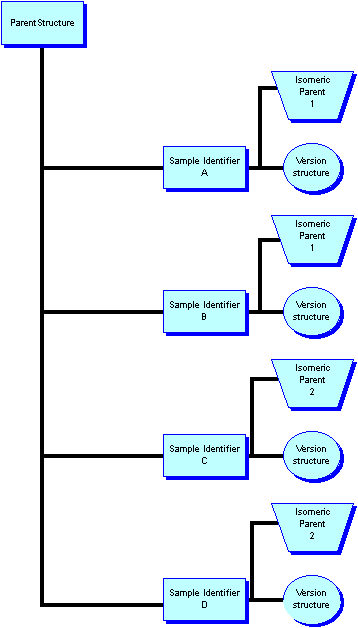
In general, all constituents of a multi-component compound are not equally important for the process in hand. If we restrict ourselves to some sort of biological assay or property measure such as logD or pKa, then these are easily understood as reflecting the presence of a parent molecule. Data such as aD reflect the presence of isomeric parent molecule. Note that neither of these parents molecules actually exist as physical entities, in the Daylight sense they are identifiers or names, about which, data exist.
Data such as melting point are clearly about a particular sample, as are the experimental results of both physicochemical and biological assays. A version molecule structure may also have been assigned to this sample perhaps a salt or solvate or even a impure isomer.
Calculated data such as clogP are about the parent molecule whereas a rubicon structure is a datum about the isomeric parent. An x-ray structure on the other hand is a datum about the sample, and is related to the version structure. Molecular formulae or weights can refer to version or parent and thus must be clearly defined. This hierarchy can be illustrated. These relationships map clearly onto the the THOR model and the definitions of identifiers and data. Note that the sample is identified by some arbitrary name. The version structure is a datum about the sample identifier, it does not differ in principle from any other data assigned to the (hopefully ) white crystalline powder.
A benefit of this model is that data, which come from a flat file such as an sdf file, are restrained within a THOR subtree, it is also important to note that whilst the structure assigned to the sample may be the same as either the parent or isomeric parent, that is purely coincidental. This strict hierarchy ensures that the data are associated with the correct identifier in the tree. This can be illustrated using the depict algorithm.
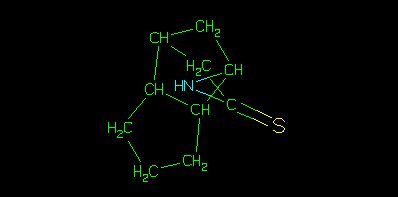
The above picture is generated from the parent smiles using smi2gif(), much like clogP would be using clogp(). Whereas
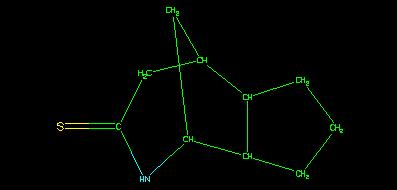
is generated from the version smiles and the associated 2D coordinates, still using smi2gif().
![]() Thanks
Norah for getting smi2gif()to read coordinates.
Thanks
Norah for getting smi2gif()to read coordinates.
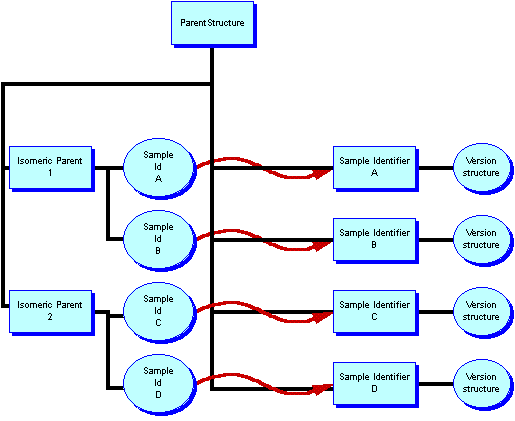
Pictorially the current ( v471) VCS THOR model is, for a parent with two isomers and each having two samples: -
This structure will be simplified in later versions to be
This is possible in the THOR model by making use of the non-identifier lookup. The isomeric parent structure is now seen as being data about the sample.
The need to take care about the data relationships cannot be emphasised too highly. An example is clear from the NCI AIDS screening results October 99 release. The structure files contain 3D coordinates generated by Gasteiger's group using Corina. However there is no stereochemistry in the original structure files. Thus NSC 624151 ( 120586-49-4 ) and NSC 624152 (120586-50-7 )are given the same 3D structure as an arbitrary choice is made in the conversion. However because this structural assignment is simply data about the sample identifier, replacing it with the corrected structure does not affect the relationship between the sample identifier and the biological data or the external identifier (CAS Number ). The situation is exacerbated by the fact that the sd format does not allow 2D and 3D coordinates to be held in the same file, so it is not clear that the choice of stereochemistry is arbitrary. Note that retaining information about the hashes and wedges is not sufficient as the creation of the 3D coordinates may have altered the orientation.
This database also provides a illustration of why the structure hierarchy is necessary. The Corina program allows the user to input a salt, thus guanidine sulphate NSC 7296 is converted faithfully into a 3D structure with the guanidine and sulphate entities separated by 10Å. Someone using the data for pharmacophore searching, may well not appreciate until it is too late that there are no bonds between!!!. It would be more valuable to calculate 3D on parent structures, even more valuable if the valence bond models used to generate the 3D coordinates were consistent.
BUT DOES IT WORK AND OFFER REAL ADDED VALUE
For the meeting there are three database sets.
The network arrangement for the meeting reflects the trend in major pharmas to have a central remote large server and also the power of the component solution where clients and servers can be changed at will, even running different versions of the software. Everyone does not have to have the same client, simply an appropriate one. Equally the company can make appropriate decisions about the hardware it uses for its servers.
DEMOS
OUTSTANDING ISSUES
Please provide feedback through the meeting to any of the Daylight krewe or by email.
Daylight Chemical Information
Systems, Inc.
info@daylight.com
{kind=link}
{kind=link}