VisualiSAR: A Web-based SAR Tool
Parke-Davis Pharmaceutical Research
Division of Warner-Lambert Company
2800 Plymouth Road, Ann Arbor, MI 48105, USA
This is an HTML version of a talk given at
Daylight MUG 99, Santa Fe, NM
February 23-26, 1999
Overview of presentation
-
Introduction to VisualiSAR technologies
-
Features and Scope of VisualiSAR
-
Current Developments & Spinoff Work
-
Improved alignment of Daylight depictions
-
Comparison of different fingerprint types for clustering
-
Evaluation of cluster level selection methods
The origins of VisualiSAR
-
We wanted to develop the Stigmata and Modal Fingerprint idea and make it
more accessible
-
We saw the potential for using the technology for analyzing 'fuzzy' high-volume
screening data
-
finding clusters of active compounds
-
highlighting commonality within the clusters
-
comparing with similar, inactive compounds
-
A tool for doing this could also have application for general 2D structure
browsing. It should be as easy to use as possible.
VisualiSAR techniques
-
Ward's Clustering
-
for grouping similar compounds together
-
Modal Fingerprints / Stigmata
-
for sorting compounds and highlighting similarities
-
Web Interface
-
for easy use, platform independence and interoperability
Technique 1: Ward's clustering
-
Hierarchical, agglomerative clustering method
-
Begins with each compound in its own cluster, then iteratively merges clusters
until there is just one cluster, producing a cluster hierarchy
-
We use binary fingerprints as the descriptors
-
Similarity measure is Euclidean distance between cluster centroids
-
'Problem' of which level in the hierarchy to select
Technique 2: Modal fingerprints and Stigmata coloring
The diagram shows a list of fingerprints on the
left. The generalized modal shows the counts for each of the bits in the
set of fingerprints. The specific modal may then be calcualated - for instance,
the modal at the 75% level is shown, which has a bit set if at least 75%
of the compounds have that bit set. Once a specific modal has been calculated,
various modal measures can be calculated for each fingerprint, like MSIM
(tanimoto similarity to the modal), MODP (fraction of modal in common with
the fingerprint) and PMOD (fraction of fingerprint in common with the modal).
The Stigmata coloring scheme can be used to color atoms by the fraction
of the paths that pass through the atom that are represented by bits that
are set in the modal, that is the atoms are colored by 'commonality' to
the set.
Here are some images which give an example of how sorting a cluster
of compounds by MSIM and then using coloring can help to show the common
features to the cluster. The
first image shows the cluster without any sorting or coloring. The
second image
shows the cluster sorted by MSIM (using the 75% modal) and colored showing
the common features.
With large clusters, viewing a representative
sample of the cluster can be useful, as can viewing the top
and bottom-ranked compounds from the set:
Technique 3: VisualiSAR Web interface
The fingerprint manipulation toolkit lies behind
much of the functionality of VisualiSAR. It is a set of C programs that
work on structures in a common format (based on TDT) for clustering, general
processing, fingeprint analysis and display. The programs can read and
write from standard input and output, so can easily be piped together in
Unix, and used from Perl scripts. Some of the programs utilize the Daylight
toolkit, although the general format is independent of fingerprint type.
VisualiSAR is one example application that uses a Perl
/ CGI interface on top of the fingerprint manipulation toolkit.. It
is written in Perl, and is interacted with through a CGI / HTML interface.
VisualiSAR uses standard HTML, with no Java or Javascript. Our philosophy
was to use good information design and interface design in the development
of the interface, and then to implement the interface using the simplest
technology possible.
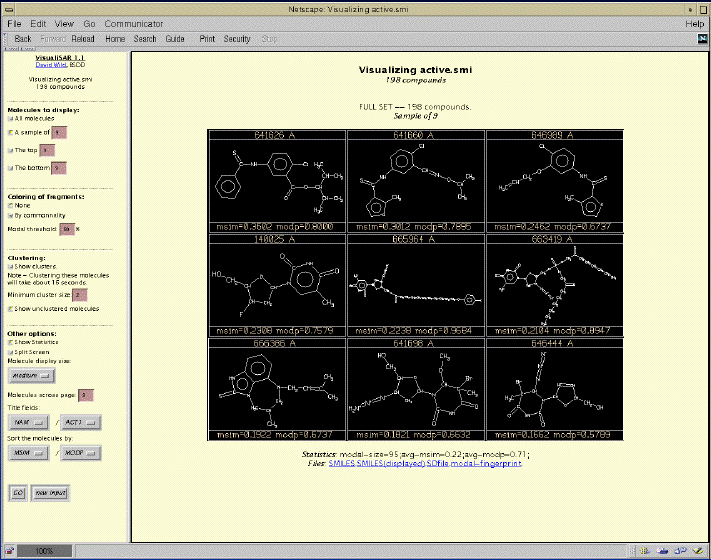
The opening screen is where compounds can be
supplied as a SMILES or SD file, or pasted into the paste box. VisualiSAR
then shows an initial view of the data set, with
a sample of nine compounds (representing different levels of similarity
to the modal) shown. The toolbar on the left allows the user access to
the functionality of VisualiSAR. After clustering,
the user can scroll through the clusters, or jump directly to a particular
cluster using the links on the left. Here, each cluster has also been colored
by commonality to the modal of the cluster.
VisualiSAR features
-
Input via SMILES or SDFILE
-
Can accept cutting and pasting e.g. from Excel or JMP
-
Clustering based on fingerprints
-
Automatic prioritization of cluster levels
-
Modal analysis and color mapping of datasets or clusters, including threshold
manipulation
-
Flexible sorting options
-
Comparison with an external modal fingerprint and with other datasets
-
Export of clusters, cluster information and modal fingerprints
-
Non-Java frames-based Web interface - platform independent
VisualiSAR scope
-
Can currently handle up to 5,000 compounds (for clustering) or 50,000 (for
searching)
-
Clustering speed could be improved
-
500 cmpds = 1.5min, 5000 cmpds = 2 hours
-
can be speeded up with RNN
-
could use a faster algorithm, e.g. Jarvis-Patrick or K-Means
-
finding optimal level slows things down further
-
Could handle >50,000 compounds by externalizing similarity search
-
if Merlin could accept a fingerprint for a similiarity search, then it
could be used for modal similarity searching
-
Requires special software for generating color mapping
-
atom-fingerprinting is available for Daylight fingerprints, and is being
investigated for BCI fingerprints
-
is computationally intensive
An example SAR strategy with VisualiSAR
-
Collect and cluster all compounds
-
Sort each cluster by activity or similarity to the modal
-
Use Stigmata coloring to highlight the similarities and differences within
the clusters
-
Look for the key differences within clusters that cause a large change
in activity
A good example is a cluster
of penicillin-like compounds, with different bioavailabilities (shown
beside the name at the top), sorted and colored by similarity to the modal.
The effect of small changes in structure on bioavailability can be seen
- for example, the addition of a methyl (highlighted in green)in ampicillin
more than doubles its bioavailbility over penicillin. Note also, that penicillin
is sorted to the top as it is the most 'representative' compound of the
set (the highest value of MSIM) and the compounds reading right and down
become more unusual.
A different way of viewing compounds is to just cluster the actives,
and then search the inactives for similar compounds to those in the active
cluster (done by sorting and coloring the inactives by similarity to the
modal of the active cluster). Thus features that may be responsible for
activity and inactivity can be highlighted. An active cluster and similar
inactives can be compared using the split-screen capability
of VisualiSAR (active cluster at the top).
Summary
-
By presenting compounds in the right way, you can make discernment of chemical
similarity and difference easier
-
There are a number of ways of visually identifying structure-activity relationships
-
Finding a cluster of actives and sorting and coloring the inactives by
similarity to the modal of the actives
-
Clustering actives and inactives together and looking for small changes
in structure which result in large changes in activity
-
A structure browsing and exploration tool like VisualiSAR can help in any
situation where there are more than a handful of compounds to be studied
Future developments
-
Explore the use of other fingerprint types
-
Cluster more efficiently
-
use an RNN implementation of Wards
-
or link in with Daylight Jarvis-Patrick Clustering
-
Cluster more effectively
-
different fingerprint types
-
hierarchy level selection methods
Spinoff fingerprint & clustering research (in progress)
-
What kind of fingerprints are best for clustering compounds together into
chemical series?
-
MACCS - 166 bits each representing a ?chemically relevant? fragment
-
Daylight - structural sequences in a compound hashed onto 2,048 bits
-
Unity - 60 fixed fragments plus 928 hashed from compounds
-
BCI - can generate fragments or use a pre-defined dictionary
-
How can we select a level from a Wards clustering hierarchy that most closely
represents the chemical series present?
-
Methods mainly selected from:
-
Milligan & Cooper, Psychometrika, 50, 2, 1985
Algorithm for improved alignment of depictions
To align depictions A and B:
-
Normalize coordinates of A and B
-
Store four sets of coordinates for B: as is, flipped horizontally, flipped
vertically, and flipped horizontally and vertically
-
For each atom in A, sum the distances between the atom and each atom in
each coordinate set of B that has the same geometric environment (atom
type and number of bonds)
-
Sum this value over all the atoms in A for each coordinate set, and choose
the coordinate set with the lowest value as our preferred depiction
This is shown in before and after
depictions
Acknowledgements
-
Parke-Davis
-
George Cowan - Algorithm design
-
T.J. O'Donnell - Web development
-
Alain Calvet, Christine Humblet
-
Daylight
-
Norah McCuish - Original Stigmata code, code for SMILES depiction in GIF
-
Jeremy Yang - Integrated atom fingerprinting into toolkit
If you are viewing this at MUG99, you may
try out VisualiSAR
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}