
| Dayblob: an ORDBMS-oriented
Dave Weininger, Daylight
|
|
| Dayblob: an ORDBMS-oriented
Dave Weininger, Daylight
|
In addition to robustness, it was required that the interface support changes on both sides (dayblob and Oracle Cartridge) ... possibly dramatic changes. On the dayblob side, such changes might include new searches, new object types (e.g., large molecules, combinatorial libraries) and multithreading support. On the Oracle side, it is likely that communication prototol will change in the 8.2 server (shared memory objects). In any case, it is certain that both Oracle and Daylight are moving towards exploitation of 64-bit architectures, but in different time-frames. The new object interface is designed to allow such changes while maintaining backwardly compatible behavior.
High-performance molecular structure processing is of very high priority to everyone involved with this project. This is awkward, because real-world RDB systems come with terrible overhead penalties. To get around this problem, a novel BLOB-based architecture was developed and implemented. When used on a capable server, resulting performance is extremely high.
By design, the Chemistry Cartridge was not designed to support a specific set of applications. Target applications are those to be developed by Oracle, Daylight, end-users and/or third-parties. The capabilities of dayblob are defined in terms of chemical objects. It is expected that a common mapping onto SQL syntax will be adopted and that this will be suitable for use with expected applications (e.g., registration, inventory control) and also with those that we haven't thought of yet.
This project is designed to produce a industrial-strength database system which is suitable for use with all chemical data sets, e.g., 10's of millions of structures, millions of reactions, strange and huge molecules, etc. However, sheer capacity was considered a secondary design criteria. For practical reasons, the current system is designed with reasonable limits (rather than without them), i.e., a few million molecules and reactions on current server hardware.
dayblob was designed as pure component software and not to be "Daylight-centric" ... at least, as much as possible in a SMILES-based chemical information system. This package doesn't know about datatypes, IDs, datatrees, or histlists; it doesn't use Daylight option manager, license manager or error handler, in fact, it does no I/O at all except via the BLOB. Ideally, users of a Chemistry Cartridge application shouldn't need to know that they're using Daylight Software, except that it goes real fast and, of course, they're smilin'.
A specialized object interface was developed for this project (the "db" interface). It is largely modelled on Daylight's "dt" object interface but is an entirely independent entity. Many of the same types of object are supported ... e.g., integers, strings, objects, sequences of objects ... but using neutral types allows us to change either side without changing our interface. For instance, one side of the partnership can move from pure 32-bit to LP64 without distrupting the other.
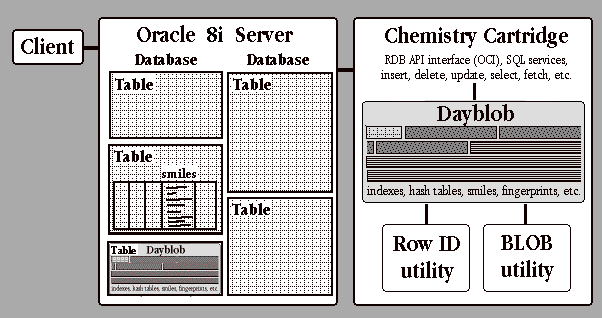
Support for some RDB-specific objects is provided. Row IDs are essential to the RDB data model and are treated as short variable length binary objects (BOBs). BLOBs ("binary large objects") are complex objects which are accessed via contexts (CXTs) and object locators (LOCs).
In a traditional RDB environment, such requirements are mutually contradictory. However, the novel approach of operating entirely within a BLOB (suggested by Sam Defazio and implemented by Cathy Trezza) appears to meet these requirements. The idea is that a component operates entirely within a single chunk of persistent storage (the BLOB). BLOB storage is managed by the RDB server via an ORDBMS interface such as OCI. From the database's POV, the BLOB is just a bunch of bits in a table and the software component is an extensible indexing method which uses these bits. From the component's POV, it can do anything it likes within the BLOB, e.g., run a fast specialized database of its own. Cool.
Aside from the calling program, dayblob requires two external utilites: one to define and manage "Row IDs" and one to manage the BLOB. BLOB management is done via contexts (CXTs) and object locators (LOCs). BLOBs are accessed in discrete readonly or read/write segments to enable efficient caching.
For example, 243 superstructures of the cefalosporin-g1 moiety are known to exist among the 37037 structures in the test database wdi93. This search was done on the same machine using dayblob and merlinserver, then the results were examined for correctness and relative speed. In this case, dayblob completed the search correctly in 0.68 seconds, which is 85% of the time used by merlinserver461 (using 1 CPU only).
Selecting a current high-end workstation (Sun Ultra60) for comparison, for typical structural searches, dayblob is about the same speed as the current merlinserver461 when run with 1-CPU (30% slower to 15% faster, depending on query). Including pathological cases, it is 2.5x slower.
A fixed-size buffer is currently used for BLOB-probing, reducing the number of required blob-manager interactions and increasing performance. This limitation could be changed or removed (with a speed penalty). Current RDB implementations impose a more restrictive limit (2000, 4000) which may be removed in future RDB versions.
Another consequence of the current buffering method is that dayblob always uses 20000 bytes more than is theoretically required (i.e., even after a "crunch"). No longer an issue in 46208.
Row IDs in RDBs are complex than they appear! They not only identify the row in a table, but also things like the table in a database, the database in a server and possibly even the database on a filesystem and the server on a network of servers. The largest binary Row IDs are now 14 bytes (we think) but there's a possibility that this might increase in the future. Dayblob views Row IDs as variable length binary objects so there's no theoretical limitation on Row ID size per se. In practice, 32B chunks are used for communication with the RDB.
Entries are made in dayblob whenever data is INSERTed into a SMILES column in an appropriately configured table. All indexing is done at INSERT time (or equivalent) including fingerprinting, which is a relatively slow operation (1000/min). In theory, this only has to be done once per entry, but there is no way of loading precomputed fingerprints into dayblob (e.g., for a database reload). Indexing is ~2X faster in 46208.
Dayblob is not multithreaded nor does it use program objects. However, Oracle implements parallelization at the session level.
The use of VARCHAR for SMILES-containing columns limits SMILES to 2000 (4000) characters. This limit could be removed by representing SMILES as LOBs (or CLOBs) at the cost of additional overhead.
Dayblob does not operate in the process-space of the RDB server, so communication speed between them is an issue. In practice, this presents a problem only for communication of pathologically large answer sets (possibly resulting in millions of FETCH operations). The current prototype cartridge does a creditable job of packing and buffering such data transfers, but even so, this approach is terribly slow compared to object mechanisms used by merlinserver. This problem should be resolved by future RDB versions which are expected to support shared memory object passing (e.g., Oracle 8.2).
This results in faster indexing and many minor improvments.
Although RowID orientation is retained, structures are internally indexed by absolute, unique, tautomer and graph SMILES. The v46208 API has been extended to allow such indexing to be used.
Prototype "shortcuts" have been replaced by production constructs, e.g., representation of internal objects, "buffer slop" elimination, multiple-index compression.
Dependence of functional interfaces on query contexts (which was present in the prototype) has been removed.
Oracle is a very large company (8000x larger than Daylight) which produces general purpose database systems and which derives most of its income from support, training and consulting services.
For Oracle, this meant stepping down a bit from the "one size fits all" throne, modifying the RDB interface to allow high-performance processing by a fundamentally different object model, engaging in development which was outside their proscribed beta program, not to mention having to deal with a bunch of free-thinkers ... not easy processes in a large company.
Cathy Trezza implemented a Cartridge based on a dayblob package written by Dave Weininger. During large loads, it would occasionally crash and burn. From Cathy's POV, dayblob was corrupting some of the pointers into the BLOB. From Dave's POV, the dayblob seemed squeaky clean in all simulations, and his friend "purify" agreed. Since we don't get to see each other's code, it's very easy to start pointing fingers in such a situation. But instead, we wrote and exchanged heavy-duty debugging versions and resolved the problem in a couple of miserable days of debugging. (In this case, the problem was caused by a misunderstanding of object property ownership.) It's often much easier to throw up one's hands and blame someone else than it is to dig in together and share the hard work required to resolve a problem. The results are much different, however.
This is an ongoing project, and an ongoing process. Although we are "over the hump", there is much more work to be done. The two main areas of effort remaining have to do with applications (Who defines them?, Which one first?, Who produces them?, etc.) and business models (Whose product is this, anyway?) We have every reason to expect that these issues will be addressed with the same level of creativity and cooperation that has characterized this project thus far.