Using Descriptor Counts in Clustering
BOOST: Close-Up of Leaf Nodes
1. Even with a small (2,000-compound), fairly diverse dataset, we
get most high-similarity groupings. The leaf nodes capture
- 80% of all pairings > 90% similarity
- 94% of all pairings > 95% similarity
- 96% of all pairings > 98% similarity
BOOST Leaf Node for a 2,000-Compound Dataset
(1024-bit Daylight Fingerprints)
- 16 compounds in node.
- 3 compounds have 1 hi-sim neighbor (>90%) in the dataset, and
also in node.
- 1 compound has 2 hi-sim neighbors in the dataset but only 1 in node.
- The 12 unmatched compounds in the node have no hi-sim neighbors
in the dataset.
|
Group 1
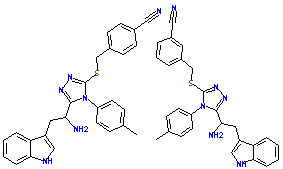 |
Group 2
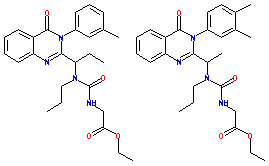 |
| 12 Unmatched Compounds |
2. In a larger dataset, condensation into small, high-similarity groups is very evident:
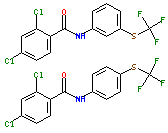
BOOST Leaf Node for a 10,000-Compound Dataset
(1024-bit Daylight Fingerprints)
Group 1
 |
Group 2
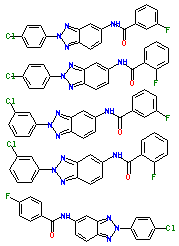 |
Group 3
1 Unmatched Compound |
- 15 compounds in node.
- 7 compounds have 6 hi-sim neighbors in the dataset, and
all are in the node.
- 5 compounds have 4 hi-sim neighbors in the dataset, and
all are in the node.
- 2 compounds have 2 hi-sim neighbors in the dataset, but only 1 in node.
- The 1 unmatched compound has no hi-sim neighbors
in the dataset.
|
3. With really large datasets, high-similarity groupings can be larger than the
leaf nodes, so we do several iterations.