| A "Bit" Larger Database |

|
| A "Bit" Larger Database |
|
THORTM database size has become an issue because Daylight users have reached the 2GB file size limit. This presentation will feature an overview of the database scheme, the reason for the current capacity limitation, and the way we are increasing the limit to 16GB.
Overview
Build a THORTM database larger than before.
Why are we doing it?
Users have reached the 2GB database limit.
How are we doing it?
Take advantage of the current quantized 32-bit addressing on 64-bit architectures.
What do we get?
A "bit" larger database limit, namely 16GB.
What are we doing?
Also, we would like to be compatible with the current servers and existing databases.
Further, we would like to make the transition to larger databases seemless.
Why are we doing it?
Also, we're doing it because if you haven't reached the limit, you probably will. Given that we're constantly seeking answers to questions and like to store relevant information, our base of knowledge (THORTM database) needs to grow.
Further, interesting things happen when there are no limits. The only limitation is our imagination, but that's not really a limitation either. Let's not have boundaries and see what happens!
How are we doing it?
Database Scheme

Data is accessed by keyword through an intermediate indexing mechanism, called a hash table. The hash table is stored in a separate file with the same name as the primary data file with the .HP extention. A hash function, HASH(keyword), is used to index the data efficiently.
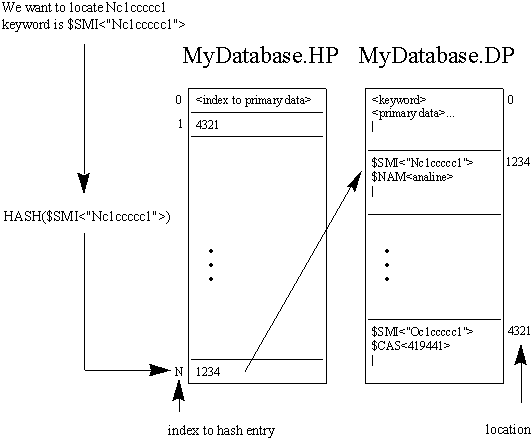
The ElfHash routine, which is used to index UN*X libraries, is an example of a hash function.
Primary data may contain other keywords, which may also be used to access the data. These other keywords, called cross references, and the hash table for it are stored in a separate pair of files with the same name as the primary data file with the .DX and .HX extenstions.

Information and attributes about the database, i.e., version, are stored in description file with the same name as the primary data file with the .THOR extention.

|

|
32-bit Addressing

Each entry in the primary data file, called a data record, contains three 4-byte unsigned integers, called a data header, plus the data itself.

All the datatypes (except for the data itself) are 4-byte unsigned integers, therefore, the database size limit stems from having only 32 bits for indexing into a file. Actually, since 32-bit operating systems use signed integers, we're effectively utilizing 31 bits and can index up to 2GB (231-1 bytes), instead of 4GB.
Quantized 32-bit Addressing
Method Shift32. Use 34-bit addressing by shifting the high 32 bits two bits to the right before writing a location and two bits to the left after reading a location. For example, before writing, bit 2 would become bit 0, bit 3 would become bit 1, and so on. The opposite would happen after reading. The advantage would be a larger database limit of 16GB (234-1 bytes). This method has been implemented and has passed preliminary "in-house" testing. Unfortunately, it's not backwards compatible with current addressing. Further, we would need to detect database format or reformat existing databases (supply ThorDbFix).

Method Roll32. Use 34-bit addressing by rolling bits 33 and 34 to bits 0 and 1 before writing a location and vice versa after reading a location. As above, the advantage would be a larger database limit of 16GB (234-1 bytes). The neat thing is that it is backwards compatible with current servers! This method is scheduled for our 4.71 product release.

Method Files32. Use bits 31, 1 and 0 to indicate one of eight sets of database files. For example, all bits off (000 as it always is now) indicates the hash entry and data record files we've been using. Now, let one bit on (001, 010, 100) refer to set 2, 3, and 4 of the hash entry and data record files, two bits on (011, 101, 110) refer to set 5, 6 and 7, and all bits on (111) refer to set 8. The advantage would be a larger database limit of 16GB (8x 2GB) and would also be backwards compatible with current servers.TM The advantage of this method is that it would work on 32-bit architectures, but requires the complexity of choosing the proper set of files for I/O.

64-bit Addressing
Method Port64. Change 4-byte locations to 8 bytes; a full-blown 64-bit port .
An obvious advantage is that the database size would be virtually unlimited (or so it would seem) at 18 million terrabytes (264-1 or 18,446,744,073,709,551,616 bytes)! A consequence would be each hash entry and data header would grow by 4 bytes. A database with 2M records would grow by 8MB by converting to the 64-bit format.

Method Squeeze64. Discontinue the hash entry scatterkey and data header key length and use the 4 bytes to make 8-byte locations.
As above, the advantage would be the virtually unlimited database size. The consequence of discontinuing the skatterkey would be some loss of efficiency. On the other hand, the scatterkey becomes ineffective when the keyword chain length is large. Also, the keyword length can be computed from the first datum in the data, so using these two fields should not significantly impact performance.

What do we get?
The pros and cons of various methods for increasing the database size limit are summarized below:
Method | Pros | Cons |
|---|---|---|
Shift32 | 16GB database size limit | not backwards compatible ThorDbFix required |
Roll32 | 16GB database size limit backwards compatible | can't think of any |
Files32 | 16GB database size limit backwards compatible works on 32-bit architectures | database file set complexity |
Port64 | virtually unlimited database size | increased hash entry and data record sizes not backwards compatible ThorDbFix required |
Squeeze64 | virtually unlimited database size | some loss of efficiency not backwards compatible ThorDbFix required |
So, we're implementing Method Roll32. The new database size limit will be 16GB.